Un entretien avec Mme Marie-Christine JAULENT, Directrice du Laboratoire d’informatique médicale et ingénierie des connaissances pour la e-santé (LIMICS, unité 1142 Inserm / Sorbonne Université / Université Sorbonne Paris Nord), Directrice de recherche Inserm
LIMICS : l’intelligence artificielle au service de l’innovation en santé
Pourriez-vous nous présenter les chiffres-clés et l’expertise du LIMICS en e-santé ?
Le LIMICS est une unité de recherche mono-équipe et interdisciplinaire en informatique et informatique médicale axée sur le développement de systèmes décisionnels innovants. Placé sous la tutelle de l’Inserm, Sorbonne Université et Université Sorbonne Paris Sud, le laboratoire compte 55 membres dont 38 permanents et 12 post-doctorants. Il collabore en outre avec 5 sites de l’AP-HP (hôpital Tenon, hôpital Avicenne, hôpital Rothschild (DSI AP-HP), hôpital La Pitié Salpêtrière, hôpital Trousseau) et accueille l’équipe du CHU de Rouen en charge du développement du CiSMeF (catalogue et index des sites médicaux de langue française) et de HeTOP (health terminology – oncology portal).

Quels sont vos principales thématiques de recherche ?
Nous travaillons selon deux grands axes : l’ingénierie de connaissances et les systèmes d’information en santé d’une part, l’aide à la décision et l’intelligence artificielle d’autre part. L’ingénierie des connaissances en santé nous conduit à formaliser des guides de bonnes pratiques et à élaborer des ontologies de domaine en médecine qui permettent d’annoter des données de santé, qu’elles soient enfouies dans des sources explicites (articles scientifiques, livres de références, dossiers de patients…) ou implicites (nées de l’observation). Cette formalisation rend les données de santé exploitables par les algorithmes.
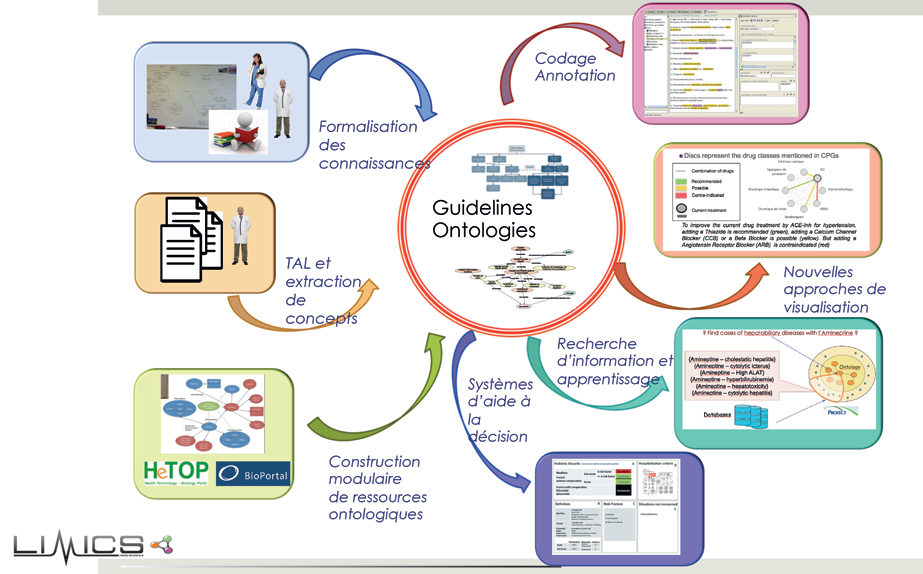
À titre d’exemple, nos travaux ont contribué à des projets européens de recherche sur les personnes atteintes de plusieurs pathologies chroniques. L’objectif était de réconcilier les guides de bonne pratique et de faire dialoguer les différentes spécialités médicales au bénéfice du patient pour élaborer des plans de soins consensuels et optimiser les traitements. Quant aux ontologies informatiques (des modèles de données représentatifs d’un ensemble de concepts dans un domaine et des relations entre ces concepts), elles sont utiles pour décrire des connaissances à des fins comparatives et permettent aux algorithmes d’intégrer des données hétérogènes. Il s’agit de donner du sens aux données pour pouvoir les partager et les réutiliser correctement. Pour ce faire, les données sont « entreposées » et annotées à partir de connaissances plus générales. Elles peuvent notamment être réutilisées pour faire de la recherche et raccourcir le temps de l’innovation en affinant les critères d’inclusion d’un essai clinique. C’est de l’interopérabilité sémantique : on donne du sens aux données dans un contexte différent de celui de leur production.
Quid de la valorisation des connaissances implicites ?
Nous recherchons les informations potentiellement intéressantes issues des données collectées pour le soin ou la recherche susceptibles de représenter des connaissances nouvelles. Les données publiques générées par l’e-santé, les dossiers des patients (dont l’imagerie médicale), la silver économie et les objets connectés fournissent la matière première des algorithmes d’apprentissage, transcendant les frontières disciplinaires et géographiques. Il s’agit de systèmes de santé auto-apprenants qui fonctionnent en quatre temps : collecter, annoter et structurer pour rendre les nouvelles données interopérables et intégrables ; puis générer de nouvelles connaissances ; les opérationnaliser dans des systèmes d’aide à la décision ; évaluer l’impact et l’amélioration des pratiques.
Pourriez-vous nous donner quelques exemples de projets en cours au LIMICS ?
Depuis seize ans nous travaillons avec l’ANSM sur un important projet de pharmacovigilance. L’IA est très utile dans ce domaine car elle donne des pistes pour repérer des signaux faibles à partir des témoignages d’internautes sur les réseaux sociaux. Il est cependant délicat de juger de la pertinence d’un tel signal parmi des millions d’autres. Cela dit des études rétrospectives sur le Mediator nous ont permis de déterminer des associations entre ce médicament et ses effets indésirables avant que les premiers cas officiels soient signalés. Dans ce type de sujet, les algorithmes de traitement automatique des langues sont essentiels pour analyser automatiquement des données de santé textuelles.
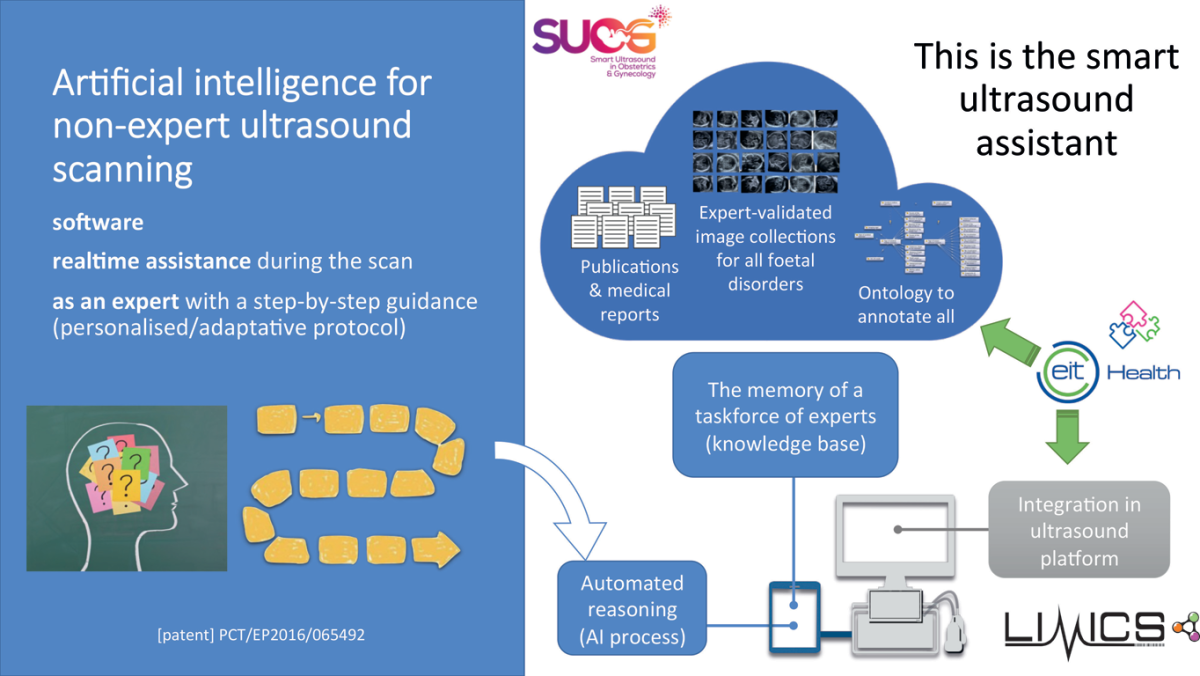
Quels sont selon vous les principaux défis à relever pour aboutir à des systèmes d’information en santé toujours plus innovants ?
Nous aurons à résoudre des problèmes éthiques dus aux erreurs commises par les algorithmes : qui endosse la responsabilité dans ce cas ? Pour ma part je prône une éthique du numérique pour encadrer l’utilisation des systèmes d’intelligence artificielle. Par ailleurs l’IA est prometteuse pour vérifier l’intérêt thérapeutique de nouvelles molécules mais on est loin de tout maîtriser : les systèmes d’IA sont incapables de dire pourquoi ils ont pris telle ou telle décision et ne peuvent pas davantage découvrir de nouvelles choses par eux-mêmes. En revanche ils peuvent voir ce que l’homme ne voit plus à l’œil nu, du fait de la masse toujours croissante de données à analyser. Ils sont donc d’une aide précieuse pour accélérer la recherche de nouveaux médicaments.
Publié à l'origine dans ©Parlementaires de France Magazine, désormais ©Research Innov France.
{kind=link}